
For the sixth year in a row Itema has hosted an Eclipse DemoCamp in Trondheim. And even though I might be biased; I would have to say it was a real pleasure. There was the usual, fairly small crowd and a few new faces. The friendly atmosphere, excellent food and beverages and really top notch presentations made it one of my highlights of the Eclipse-year.
Over the years, there has been a clear trend towards more science content in our event. Personally I really enjoy this. There are plenty of talks on how to do this and that with Eclipse, but not so many on how Eclipse technologies are used in science and research. I hope that next year we can make better use of this knowledge and have even more attendants from the science community.
After a warm welcome by Lone Madsen, the CEO of Itema, we saw Ralph Müller of the Eclipse Foundation give an introduction to the work of the foundation and how open source has changed the way one can do business in consulting and in the software industry in general.
Next up was Hallvard Trætteberg, a professor at NTNU, to give us an introduction to Eclipse Sirius and how it can be used to model the genealogy of Pokemons ? Hallvard often uses Eclipse technologies in his classes, so it was interesting to see how he leverages good documentation and API in open source projects to help students understand software development.
As a follow-up on the Sirius introduction: Erlend Stav from SINTEF ICT talked about how Eclipse Sirius is being used in a EU project to model sensors, actuators and the relationship between these in a complex structure, such as in a modern airplane. Apparently a modern Airbus has several hundred kilometers of cabling that weighs a total way-too-much, so this can be improved using smarter modules. Open source technologies is playing a big role in this. This resulting code is not open source though.
Håvard Heierli-Nesse from MARINTEK introduced us to the world of 3D modeling and the Eclipse Advanced Visualization Project (EAVP). This project is part of the Eclipse Science Working Group’s efforts to lower the bar on developing scientific applications. In particular visualization of problems and post-processing results. In this case 3D models of both. He demonstrated their current solution using a commercial rendering engine and what can be achieved with EAVP rendering using JavaFX. It was clear that EAVP has a way to go, but the point was that EAVP abstracts the rendering layer. Utilizing this technology allows you to ignore the nitty-gritty OpenGL and whatnots, so you can focus on getting your model representation right. Also he demonstrated how the numerical arrays in the Eclipse January API (also from the SWG) can be directly plugged into EAVP for rendering. He also mentioned that JavaFX is not the only rendering option for EAVP; ParaView and ORLN‘s VisIt can also be used.






Traditionally we have brought in a few speakers that have little to do with Eclipse in general. Not only because the Eclipse community in Trondheim is small, but also because it’s interesting to learn from other arenas. So this year Lars Eidnes from Itema gave us a nice introduction to machine learning and showed us the formula to get started solving certain problems using neural networks. It was a bit math-heavy according to some, but as one attendant summed it up: “Aha! That’s how they do it!”.
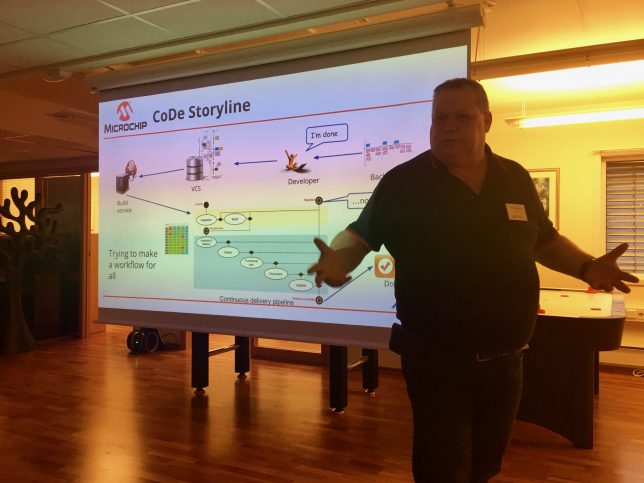
To follow that up; Per Arnold Blåsmo from Microchip/Atmel Norway explained how a small team’s use of agile practices; in a few years could grow into a pipeline of continuously deploying really complex pieces of software and hardware, in a global company, involving more than 110 developers and 1400 daily build jobs. Not unlike what Eclipse does, except what they’re doing involves a robot pulling microcontrollers from a shelf and connecting them to hardware debuggers to test the software tools as part of the Jenkins jobs. I think the lesson here was that best practices rules, even in a huge company, one just have to convince the management that the engineers knows best how to do their work. Good riddance to the Gantt charts!
Matthew Gerring from Diamond Light Source (DLS) gave us a quick update on the Eclipse Science Working Group, as well as explaining how a synchrotron works, in particular the one located in Oxfordshire, UK. You get a feel of it once you’re actually inside it and the scale is overwhelming, I counted 31 beamlines, which I think equals the number of experiments one can do concurrently, and one beamline is the size of an average sized bedroom I guess. Then he went on into talking about the numerous Eclipse based software at DLS and how they are used. He also demonstrated a new feature in DAWN, their post-processing software, allowing you to do plug-in development from within the DAWN, test it, then deploy either to the running instance or to a marketplace server for sharing. I’m glad the British and the Norwegians share the sense of humor, otherwise his stream of carefully placed jokes would fall on infertile ground. They did not.
We closed the event with a Kahoot quiz before having a couple of beers and moving to the Work-Work gaming lab (and bar).
Hei, Torkild! Unfortunately, I didn’t know about the event in advance. I am interested in Sirius talks. Did you record the video from the sessions?
No sorry, we did not record anything. You may want to ask the authors about the slides. They can be contacted through the Meetup page, where you also can sign up for future events. Hope this helps. See https://www.meetup.com/Trondheim-Eclipse-User-Group/
Really nice write-up, glad I could read all about is since I couldn’t make it this time. Sounds great, and these lines had me in stitches:
Thanks Tracy ? We missed you!